Collaborative Annotation of Semantic Objects in Images with Multi-granularity Supervisions
Lishi Zhang* Chenghan Fu* Jia Li+
* equal contribution
State Key Laboratory of Virtual Reality Technology and Systems, Beihang University
Published in ACM Multimedia, July. 2018
Dataset

There are 40 classes of ImageNet annotated by our annotation tool and LabelMe. (a,g) Tagged images, (b,h) DeepMask, (c,i) SharpMask, (d,j) Our initialization results, (e,k) Our final annotation results, (f,l) LabelMe results (ground-truth).
Approach

Framework of the proposed approach. Given a set of images tagged with ``Cat``,'' a computer agent is dynamically generated with weak, strong and flip dictionaries. It first extracts object proposals and superpixels, and the tag-related object proposals are then inferred by measuring the sparse coding length of weak and strong dictionaries. By converting the tag-related objects into the binary labels of superpixels, the human annotator can participate to flip the superpixel label or divide coarse superpixel into finer ones via mouse clicks. Such clicks are then used to form flip dictionaries which can be used to supervise the automatic refinement of subsequent images.
Benchmark
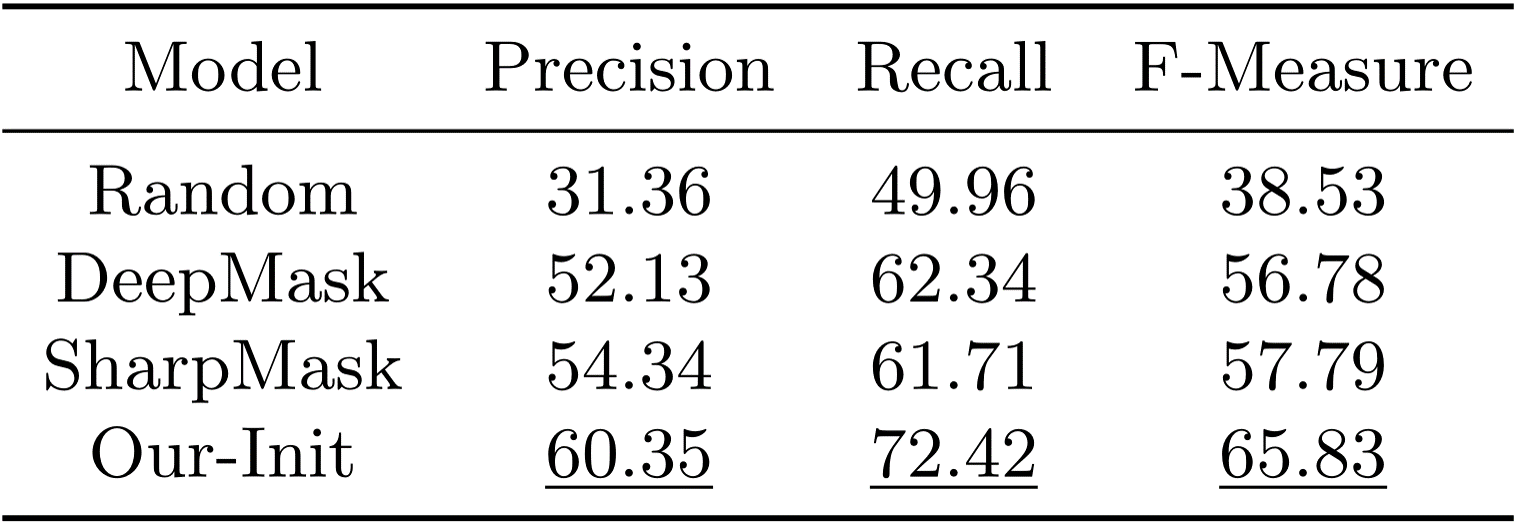
Two state-of-the-art automatic segmentation models are tested on ImageNet (40 classes ).
Citation
-
Lishi Zhang*, Chenghan Fu*, Jia Li+. Collaborative Annotation of Semantic Objects in Images with Multi-granularity Supervisions.