Primary Video Object Segmentation via Complementary CNNs and Neighborhood Reversible Flow
Jia Li Anlin Zheng Xiaowu Chen Bin Zhou
State Key Laboratory of Virtual Reality Technology and Systems, Beihang University
Published in ICCV, 2017
The Approach
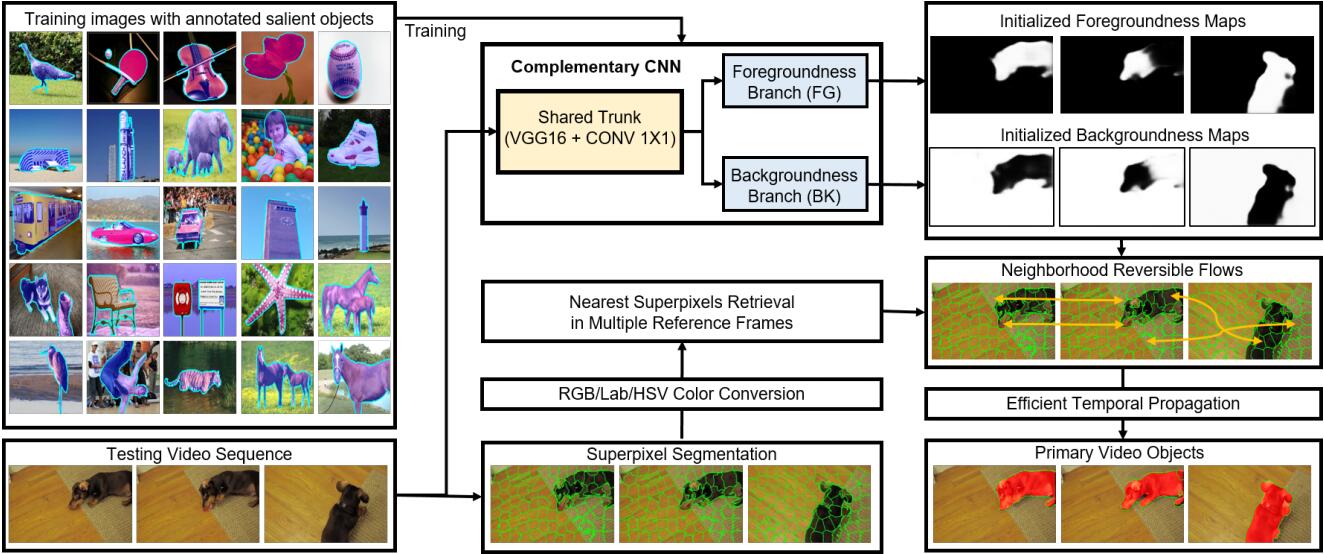
The framework consists of two major modules. The spatial module trains CCNN to simultaneously initialize the foregroundness and backgroundness maps of each frame. This module operates on GPU to provide pixel-wise predictions for each frame. The temporal module constructs neighborhood reversible flow so as to propagate foregroundness and backgroundness along the most reliable inter-frame correspondences. This module operates on superpixels for efficient temporal propagation.
Complementary CNNs
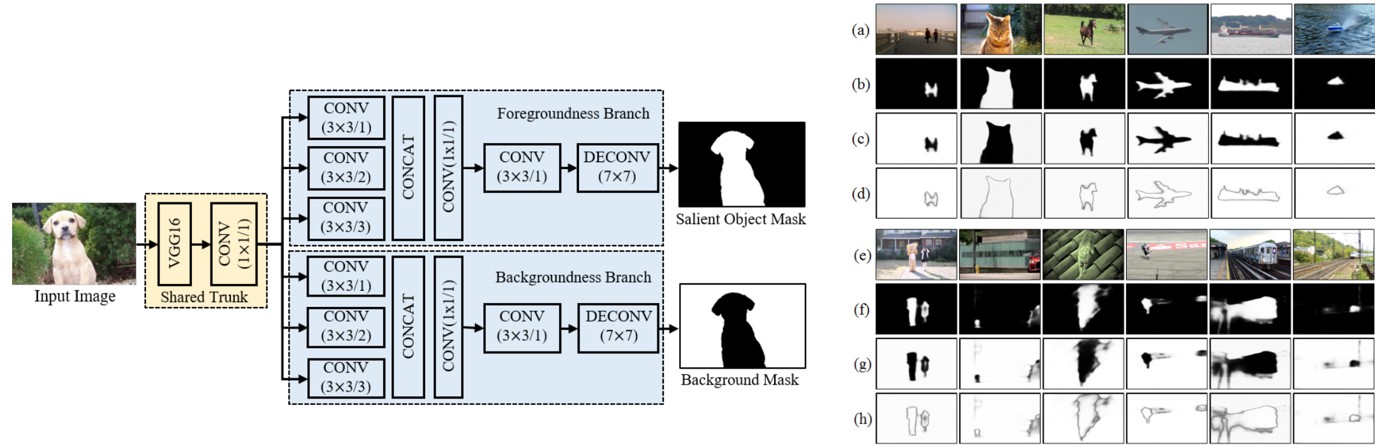
Architecture of CCNN. Here CONV (3*3/2) indicates a convolutional layer with 3*3 kernels and dilation of 2. Foregroundness and backgroundness maps initialized by CCNN as well as their fusion maps (i.e., maximum values from two maps). (a) and (e) Video frames, (b) and (f) foregroundness maps, (c) and (g) backgroundness maps, (d) and (h) fusion maps. We can see that the foregroundness and backgroundness maps can well depict salient objects and distractors in many frames (see (a)-(d)). However, they are not always perfectly complementary, leaving some area mistakenly predicted in both foreground and background maps (see the black area in fusion maps (h))
Result

Representative results of our approach. Red masks are the ground-truth and green contours are the segmented primary objects.
Citation
-
Jia Li, Anlin Zheng, Xiaowu Chen and Bin Zhou. Primary Video Object Segmentation via Complementary CNNs and Neighborhood Reversible Flow. The IEEE International Conference on Computer Vision (ICCV), 2017, pp. 1417-1425
- Paper: [CVF Open Access] [BibTeX]
- Resources: [Code]