A Benchmark Dataset and Saliency-Guided Stacked Autoencoders for Video-Based Salient Object Detection
Jia Li Changqun Xia Xiaowu Chen
State Key Laboratory of Virtual Reality Technology and Systems, Beihang University
Published in IEEE TIP, Jan. 2018
Image-based salient object detection (SOD) has been extensively studied in past decades. However, video-based SOD is much less explored due to the lack of large-scale video datasets within which salient objects are unambiguously defined and annotated. Toward this end, this paper proposes a video-based SOD dataset that consists of 200 videos. In constructing the dataset, we manually annotate all objects and regions over 7,650 uniformly sampled keyframes and collect the eye-tracking data of 23 subjects who free-view all videos. From the user data, we find that salient objects in a video can be defined as objects that consistently pop-out throughout the video, and objects with such attributes can be unambiguously annotated by combining manually annotated object/region masks with eye-tracking data of multiple subjects. To the best of our knowledge, it is currently the largest dataset for video-based salient object detection.
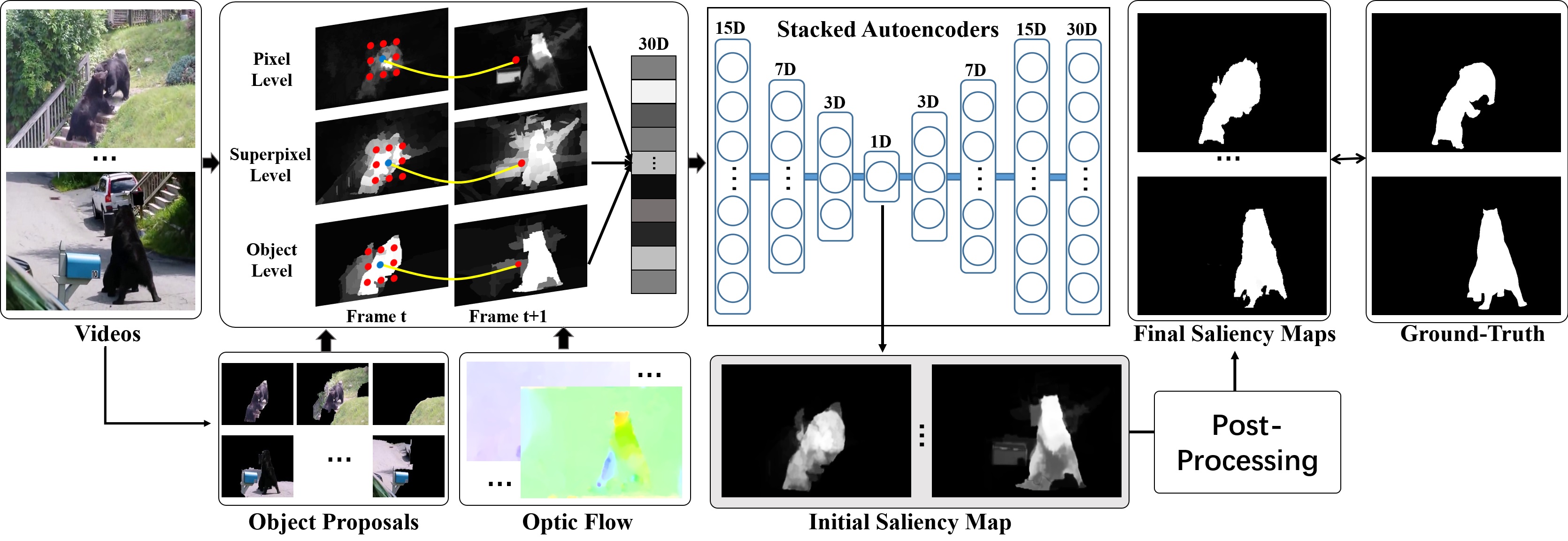
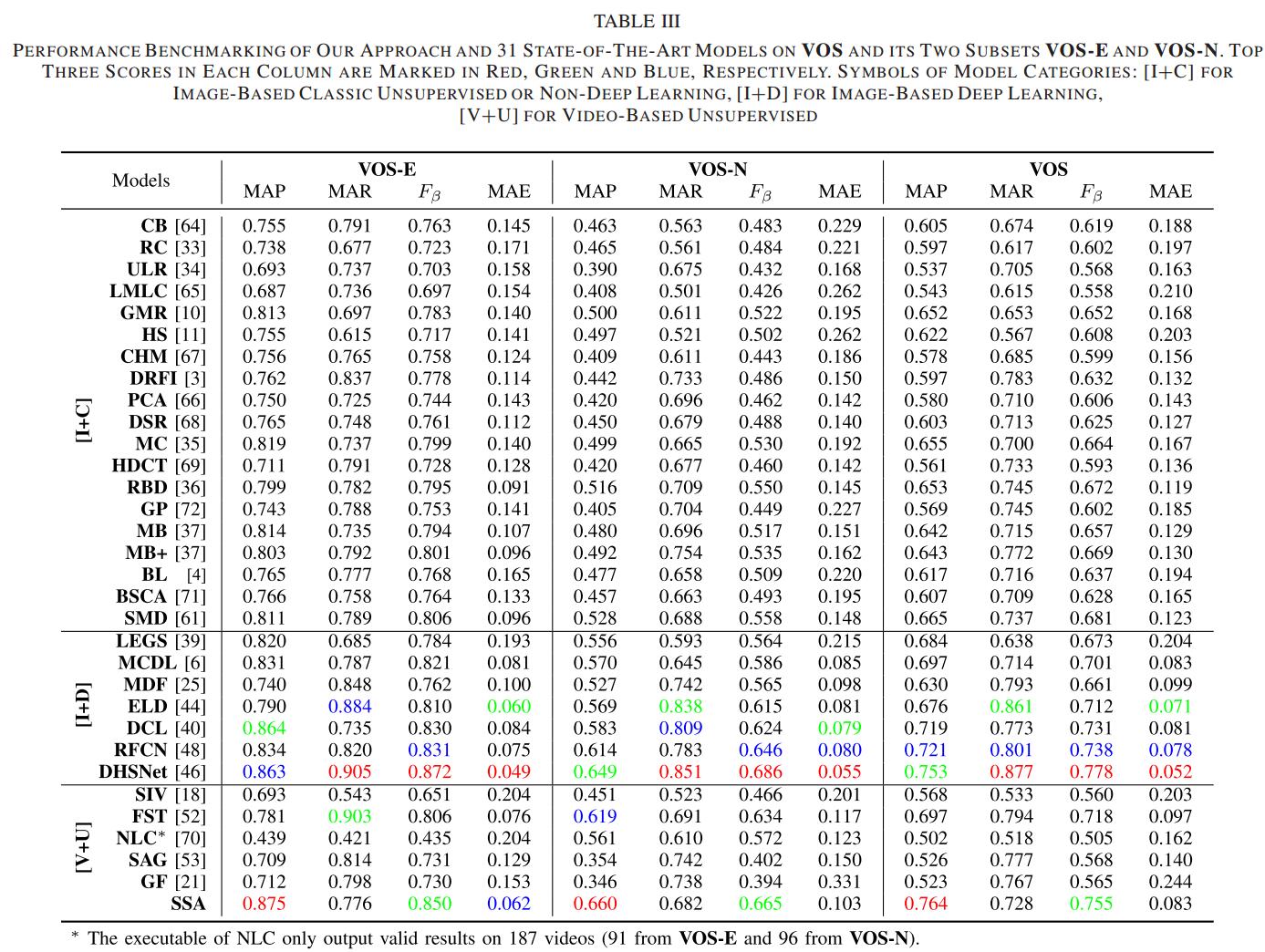
Based on this dataset, this paper proposes an unsupervised baseline approach for video-based SOD by using saliency-guided stacked autoencoders. In the proposed approach, multiple spatiotemporal saliency cues are first extracted at the pixel, superpixel and object levels. With these saliency cues, stacked autoencoders are constructed in an unsupervised manner that automatically infers a saliency score for each pixel by progressively encoding the high-dimensional saliency cues gathered from the pixel and its spatiotemporal neighbors. In experiments, the proposed unsupervised approach is compared with 31 state-of-the-art models on the proposed dataset and outperforms 30 of them, including 19 image-based classic (unsupervised or non-deep learning) models, six image-based deep learning models, and five video-based unsupervised models. Moreover, benchmarking results show that the proposed dataset is very challenging and has the potential to boost the development of video-based SOD.
Dataset
The proposed dataset VOS contains 200 videos that are grouped into two subsets according to the complexity of foreground, background and motion, including VOS-E (easy subset, 97 videos) and VOS-N (normal subset, 103 videos).
Approach
The framework of the proposed approach (Saliency-guided Stacked Autoencoders, SSA). This approach is fully unsupervised and can be used as a baseline model on VOS.
Benchmark
Thirty-two state-of-the-art models are tested on VOS (19 image-based classic unsupervised or non-deep learning models, seven image-based deep learning models, and six video-based unsupervised models).
Citation
-
Jia Li, Changqun Xia and Xiaowu Chen. A Benchmark Dataset and Saliency-Guided Stacked Autoencoders for Video-Based Salient Object Detection. IEEE Transactions on Image Processing, 27(1), pp. 349-364, Jan. 2018.